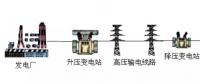
SQL on Hadoop的最新進展及7項相關(guān)技術(shù)分享
在互聯(lián)網(wǎng)企業(yè)和有大數(shù)據(jù)處理需求的傳統(tǒng)企業(yè)中,基于Hadoop構(gòu)建的數(shù)據(jù)倉庫的數(shù)據(jù)來源主要有以下幾個:
·通過Flume/Scribe/Chukwa這樣的日志收集和分析系統(tǒng)把來自Apache/Nginx的日志收集到HDFS上,然后通過Hive查詢。
·通過Sqoop這樣的工具把用戶和業(yè)務(wù)維度數(shù)據(jù)(一般存儲在Oracle/MySQL中)定期導入Hive,那么OLTP數(shù)據(jù)就有了一個用于OLAP的副本了。
·通過ETL工具從其他外部DW數(shù)據(jù)源里導入的數(shù)據(jù)。
目前所有的SQL on Hadoop產(chǎn)品其實都是在某個或者某些特定領(lǐng)域內(nèi)適合的,沒有silver bullet。像當年Oracle/Teradata這樣的滿足幾乎所有企業(yè)級應(yīng)用的產(chǎn)品在大數(shù)據(jù)時代是不現(xiàn)實的。所以每一種SQL on Hadoop產(chǎn)品都在盡量滿足某一類應(yīng)用的特征。典型需求:
·interactive query (ms~3min)
·data analyst,reporting query (3min~20min)
·data mining,modeling and large ETL (20 min ~ hr ~ day)
機器學習需求(通過MapReduce/MPI/Spark等計算模型來滿足)
Hive
Hive是目前互聯(lián)網(wǎng)企業(yè)中處理大數(shù)據(jù)、構(gòu)建數(shù)據(jù)倉庫最常用的解決方案,甚至在很多公司部署了Hadoop集群不是為了跑原生MapReduce程序,而全用來跑Hive SQL的查詢?nèi)蝿?wù)。
對于有很多data scientist和analyst的公司,會有很多相同表的查詢需求。那么顯然每個人都從Hive中查數(shù)據(jù)速度既慢又浪費資源。如果能把經(jīng)常訪問的數(shù)據(jù)放到內(nèi)存組成的集群中供用戶查詢那樣效率就會高很多。Facebook針對這一需求開發(fā)了Presto,一個把熱數(shù)據(jù)放到內(nèi)存中供SQL查詢的系統(tǒng)。這個設(shè)計思路跟Impala和Stinger非常類似了。使用Presto進行簡單查詢只需要幾百毫秒,即使是非常復(fù)雜的查詢,也只需數(shù)分鐘即可完成,它在內(nèi)存中運行,并且不會向磁盤寫入。Facebook有超過850名工程師每天用它來掃描超過320TB的數(shù)據(jù),滿足了80%的ad-hoc查詢需求。
目前Hive的主要缺點:
·data shuffle時網(wǎng)絡(luò)瓶頸,Reduce要等Map結(jié)束才能開始,不能高效利用網(wǎng)絡(luò)帶寬。
·一般一個SQL都會解析成多個MR job,Hadoop每次Job輸出都直接寫HDFS,大量磁盤IO導致性能比較差。
·每次執(zhí)行Job都要啟動Task,花費很多時間,無法做到實時。
·由于把SQL轉(zhuǎn)化成MapReduce job時,map、shuffle和reduce所負責執(zhí)行的SQL解析出得功能不同。那么就有Map->MapReduce或者MapReduce->Reduce這樣的需求,這樣可以降低寫HDFS的IO數(shù)量,從而提高性能。但是目前MapReduce框架還不支持M->MR或者MR->R這樣的任務(wù)執(zhí)行。
目前Hive主要的改進(主要是體現(xiàn)在 Hive 0.11版本上):
1. 同一條hive SQL解析出的多個MR任務(wù)的合并。由Hive解析出來的MR jobs中有非常多的Map->MapReduce類型的job,可以考慮把這個過程合并成一個MRjob。
2. Hive query optimizer(查詢優(yōu)化器是Hive需要持續(xù)不斷優(yōu)化的一個topic)
例如JOIN順序的優(yōu)化,就是原來一個大表和多個小表在不同column匹配的條件下JOIN需要解析成多個Map join + MR job,現(xiàn)在可以合并成一個MR job。
這個改進方向要做的就是用戶不用給太多的hint,hive可以自己根據(jù)表的大小、行數(shù)等,自動選擇最快的join的方法(小表能裝進內(nèi)存的話就用Map join,Map join能和其他MR job合并的就合并)。這個思路跟cost-based query optimizer有點類似了,用戶寫出來的SQL在翻譯成執(zhí)行計劃之前要計算那種執(zhí)行方式和JOIN順序效率更高。
3. ORCFile
ORCFile是一種列式存儲的文件,對于分析型應(yīng)用來說列存有非常大的優(yōu)勢。
原來的RCFile中把每一列看成binary blob,沒有任何語義,所以只能用通用的zlib,LZO,Snappy等壓縮方法。ORCFile能夠獲取每一列的類型(int還是string),那么就可以使用諸如dictionary encoding, bit packing, delta encoding, run-length encoding等輕量級的壓縮技術(shù)。這種壓縮技術(shù)的優(yōu)勢有兩點:一是提高壓縮率;二是能夠起到過濾無關(guān)數(shù)據(jù)的效果。
Predicate Pushdown:原來的Hive是把所有的數(shù)據(jù)都讀到
官方微信售電那點事兒")
責任編輯:廖生玨
- 相關(guān)閱讀
- 泛在電力物聯(lián)網(wǎng)
- 電動汽車
- 儲能技術(shù)
- 智能電網(wǎng)
- 電力通信
- 電力軟件
- 高壓技術(shù)
-

權(quán)威發(fā)布 | 新能源汽車產(chǎn)業(yè)頂層設(shè)計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設(shè)
2020-11-03新能源,汽車,產(chǎn)業(yè),設(shè)計 -

中國自主研制的“人造太陽”重力支撐設(shè)備正式啟運
2020-09-14核聚變,ITER,核電 -

探索 | 既耗能又可供能的數(shù)據(jù)中心 打造融合型綜合能源系統(tǒng)
2020-06-16綜合能源服務(wù),新能源消納,能源互聯(lián)網(wǎng)
-
新基建助推 數(shù)據(jù)中心建設(shè)將迎爆發(fā)期
2020-06-16數(shù)據(jù)中心,能源互聯(lián)網(wǎng),電力新基建 -

泛在電力物聯(lián)網(wǎng)建設(shè)下看電網(wǎng)企業(yè)數(shù)據(jù)變現(xiàn)之路
2019-11-12泛在電力物聯(lián)網(wǎng) -

泛在電力物聯(lián)網(wǎng)建設(shè)典型實踐案例
2019-10-15泛在電力物聯(lián)網(wǎng)案例
-

新基建之充電樁“火”了 想進這個行業(yè)要“心里有底”
2020-06-16充電樁,充電基礎(chǔ)設(shè)施,電力新基建 -

燃料電池汽車駛?cè)雽こ0傩占疫€要多久?
-

備戰(zhàn)全面電動化 多部委及央企“定調(diào)”充電樁配套節(jié)奏
-
權(quán)威發(fā)布 | 新能源汽車產(chǎn)業(yè)頂層設(shè)計落地:鼓勵“光儲充放”,有序推進氫燃料供給體系建設(shè)
2020-11-03新能源,汽車,產(chǎn)業(yè),設(shè)計 -
中國自主研制的“人造太陽”重力支撐設(shè)備正式啟運
2020-09-14核聚變,ITER,核電 -

能源革命和電改政策紅利將長期助力儲能行業(yè)發(fā)展
-
探索 | 既耗能又可供能的數(shù)據(jù)中心 打造融合型綜合能源系統(tǒng)
2020-06-16綜合能源服務(wù),新能源消納,能源互聯(lián)網(wǎng) -

5G新基建助力智能電網(wǎng)發(fā)展
2020-06-125G,智能電網(wǎng),配電網(wǎng) -

從智能電網(wǎng)到智能城市