企業(yè)如何實(shí)現(xiàn)對(duì)大數(shù)據(jù)的處理與分析?
隨著兩化深度融合的持續(xù)推進(jìn),全面實(shí)現(xiàn)業(yè)務(wù)管理和生產(chǎn)過(guò)程的數(shù)字化、自動(dòng)化和智能化是企業(yè)持續(xù)保持市場(chǎng)競(jìng)爭(zhēng)力的關(guān)鍵。在這一過(guò)程中數(shù)據(jù)
隨著兩化深度融合的持續(xù)推進(jìn),全面實(shí)現(xiàn)業(yè)務(wù)管理和生產(chǎn)過(guò)程的數(shù)字化、自動(dòng)化和智能化是企業(yè)持續(xù)保持市場(chǎng)競(jìng)爭(zhēng)力的關(guān)鍵。在這一過(guò)程中數(shù)據(jù)必將成為企業(yè)的核心資產(chǎn),對(duì)數(shù)據(jù)的處理、分析和運(yùn)用將極大的增強(qiáng)企業(yè)的核心競(jìng)爭(zhēng)力。但長(zhǎng)期以來(lái),由于數(shù)據(jù)分析手段和工具的缺乏,大量的業(yè)務(wù)數(shù)據(jù)在系統(tǒng)中層層積壓而得不到利用,不但增加了系統(tǒng)運(yùn)行和維護(hù)的壓力,而且不斷的侵蝕有限的企業(yè)資金投入。如今,隨著大數(shù)據(jù)技術(shù)及應(yīng)用逐漸發(fā)展成熟,如何實(shí)現(xiàn)對(duì)大量數(shù)據(jù)的處理和分析已經(jīng)成為企業(yè)關(guān)注的焦點(diǎn)。

對(duì)企業(yè)而言,由于長(zhǎng)期以來(lái)已經(jīng)積累的海量的數(shù)據(jù),哪些數(shù)據(jù)有分析價(jià)值?哪些數(shù)據(jù)可以暫時(shí)不用處理?這些都是部署和實(shí)施大數(shù)據(jù)分析平臺(tái)之前必須梳理的問(wèn)題點(diǎn)。以下就企業(yè)實(shí)施和部署大數(shù)據(jù)平臺(tái),以及如何實(shí)現(xiàn)對(duì)大量數(shù)據(jù)的有效運(yùn)用提供建議。
第一步:采集數(shù)據(jù)
對(duì)企業(yè)而言,不論是新實(shí)施的系統(tǒng)還是老舊系統(tǒng),要實(shí)施大數(shù)據(jù)分析平臺(tái),就需要先弄明白自己到底需要采集哪些數(shù)據(jù)。因?yàn)榭紤]到數(shù)據(jù)的采集難度和成本,大數(shù)據(jù)分析平臺(tái)并不是對(duì)企業(yè)所有的數(shù)據(jù)都進(jìn)行采集,而是相關(guān)的、有直接或者間接聯(lián)系的數(shù)據(jù),企業(yè)要知道哪些數(shù)據(jù)是對(duì)于戰(zhàn)略性的決策或者一些細(xì)節(jié)決策有幫助的,分析出來(lái)的數(shù)據(jù)結(jié)果是有價(jià)值的,這也是考驗(yàn)一個(gè)數(shù)據(jù)分析員的時(shí)刻。比如企業(yè)只是想了解產(chǎn)線設(shè)備的運(yùn)行狀態(tài),這時(shí)候就只需要對(duì)影響產(chǎn)線設(shè)備性能的關(guān)鍵參數(shù)進(jìn)行采集。再比如,在產(chǎn)品售后服務(wù)環(huán)節(jié),企業(yè)需要了解產(chǎn)品使用狀態(tài)、購(gòu)買群體等信息,這些數(shù)據(jù)對(duì)支撐新產(chǎn)品的研發(fā)和市場(chǎng)的預(yù)測(cè)都有著非常重要的價(jià)值。因此,建議企業(yè)在進(jìn)行大數(shù)據(jù)分析規(guī)劃的時(shí)候針對(duì)一個(gè)項(xiàng)目的目標(biāo)進(jìn)行精確的分析,比較容易滿足業(yè)務(wù)的目標(biāo)。
大數(shù)據(jù)的采集過(guò)程的難點(diǎn)主是并發(fā)數(shù)高,因?yàn)橥瑫r(shí)有可能會(huì)有成千上萬(wàn)的用戶來(lái)進(jìn)行訪問(wèn)和操作,比如火車票售票網(wǎng)站和淘寶,它們并發(fā)的訪問(wèn)量在峰值時(shí)達(dá)到上百萬(wàn),所以需要在采集端部署大量數(shù)據(jù)庫(kù)才能支撐。并且如何在這些數(shù)據(jù)庫(kù)之間進(jìn)行負(fù)載均衡和分片也是需要深入的思考問(wèn)題。
第二步:導(dǎo)入及預(yù)處理數(shù)據(jù)
采集過(guò)程只是大數(shù)據(jù)平臺(tái)搭建的第一個(gè)環(huán)節(jié)。當(dāng)確定了哪些數(shù)據(jù)需要采集之后,下一步就需要對(duì)不同來(lái)源的數(shù)據(jù)進(jìn)行統(tǒng)一處理。比如在智能工廠里面可能會(huì)有視頻監(jiān)控?cái)?shù)據(jù)、設(shè)備運(yùn)行數(shù)據(jù)、物料消耗數(shù)據(jù)等,這些數(shù)據(jù)可能是結(jié)構(gòu)化或者非結(jié)構(gòu)化的。這個(gè)時(shí)候企業(yè)需要利用ETL工具將分布的、異構(gòu)數(shù)據(jù)源中的數(shù)據(jù)如關(guān)系數(shù)據(jù)、平面數(shù)據(jù)文件等抽取到臨時(shí)中間層后進(jìn)行清洗、轉(zhuǎn)換、集成,將這些來(lái)自前端的數(shù)據(jù)導(dǎo)入到一個(gè)集中的大型分布式數(shù)據(jù)庫(kù)或者分布式存儲(chǔ)集群,最后加載到數(shù)據(jù)倉(cāng)庫(kù)或數(shù)據(jù)集市中,成為聯(lián)機(jī)分析處理、數(shù)據(jù)挖掘的基礎(chǔ)。對(duì)于數(shù)據(jù)源的導(dǎo)入與預(yù)處理過(guò)程,最大的挑戰(zhàn)主要是導(dǎo)入的數(shù)據(jù)量大,每秒鐘的導(dǎo)入量經(jīng)常會(huì)達(dá)到百兆,甚至千兆級(jí)別。
第三步:統(tǒng)計(jì)與分析
統(tǒng)計(jì)與分析主要利用分布式數(shù)據(jù)庫(kù),或者分布式計(jì)算集群來(lái)對(duì)存儲(chǔ)于其內(nèi)的海量數(shù)據(jù)進(jìn)行普通的分析和分類匯總等,以滿足大多數(shù)常見(jiàn)的分析需求,在這方面,一些實(shí)時(shí)性需求會(huì)用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL的列式存儲(chǔ)Infobright等,而一些批處理,或者基于半結(jié)構(gòu)化數(shù)據(jù)的需求可以使用Hadoop.數(shù)據(jù)的統(tǒng)計(jì)分析方法也很多,如假設(shè)檢驗(yàn)、顯著性檢驗(yàn)、差異分析、相關(guān)分析、T檢驗(yàn)、方差分析、卡方分析、偏相關(guān)分析、距離分析、回歸分析、簡(jiǎn)單回歸分析、多元回歸分析、逐步回歸、回歸預(yù)測(cè)與殘差分析、嶺回歸、logistic回歸分析、曲線估計(jì)、因子分析、聚類分析、主成分分析、因子分析、快速聚類法與聚類法、判別分析、對(duì)應(yīng)分析、多元對(duì)應(yīng)分析(最優(yōu)尺度分析)、bootstrap技術(shù)等等。在統(tǒng)計(jì)與分析這部分,主要特點(diǎn)和挑戰(zhàn)是分析涉及的數(shù)據(jù)量大,其對(duì)系統(tǒng)資源,特別是I/O會(huì)有極大的占用。
第四步:價(jià)值挖掘
與前面統(tǒng)計(jì)和分析過(guò)程不同的是,數(shù)據(jù)挖掘一般沒(méi)有什么預(yù)先設(shè)定好的主題,主要是在現(xiàn)有數(shù)據(jù)上面進(jìn)行基于各種算法的計(jì)算,從而起到預(yù)測(cè)的效果,從而實(shí)現(xiàn)一些高級(jí)別數(shù)據(jù)分析的需求。比較典型算法有用于聚類的Kmeans、用于統(tǒng)計(jì)學(xué)習(xí)的SVM和用于分類的NaiveBayes,主要使用的工具有Hadoop的Mahout等。該過(guò)程的特點(diǎn)和挑戰(zhàn)主要是用于挖掘的算法很復(fù)雜,并且計(jì)算涉及的數(shù)據(jù)量和計(jì)算量都很大,常用數(shù)據(jù)挖掘算法都以單線程為主。
總結(jié)
為了得到更加精確的結(jié)果,在大數(shù)據(jù)分析的過(guò)程要求企業(yè)相關(guān)的業(yè)務(wù)規(guī)則都是已經(jīng)確定好的,這些業(yè)務(wù)規(guī)則可以幫助數(shù)據(jù)分析員評(píng)估他們的工作復(fù)雜性,對(duì)了應(yīng)對(duì)這些數(shù)據(jù)的復(fù)雜性,將數(shù)據(jù)進(jìn)行分析得出有價(jià)值的結(jié)果,才能更好的實(shí)施。制定好了相關(guān)的業(yè)務(wù)規(guī)則之后,數(shù)據(jù)分析員需要對(duì)這些數(shù)據(jù)進(jìn)行分析輸出,因?yàn)楹芏鄷r(shí)候,這些數(shù)據(jù)結(jié)果都是為了更好的進(jìn)行查詢以及用在下一步的決策當(dāng)中使用,如果項(xiàng)目管理團(tuán)隊(duì)的人員和數(shù)據(jù)分析員以及相關(guān)的業(yè)務(wù)部門沒(méi)有進(jìn)行很好的溝通,就會(huì)導(dǎo)致許多項(xiàng)目需要不斷地重復(fù)和重建。最后,由于分析平臺(tái)會(huì)長(zhǎng)期使用,但決策層的需求是變化的,隨著企業(yè)的發(fā)展,會(huì)有很多的新的問(wèn)題出現(xiàn),數(shù)據(jù)分析員的數(shù)據(jù)分析也要及時(shí)的進(jìn)行更新,現(xiàn)在的很多數(shù)據(jù)分析軟件創(chuàng)新的主要方面也是關(guān)于對(duì)數(shù)據(jù)的需求變化部分,可以保持?jǐn)?shù)據(jù)分析結(jié)果的持續(xù)價(jià)值。
對(duì)企業(yè)而言,由于長(zhǎng)期以來(lái)已經(jīng)積累的海量的數(shù)據(jù),哪些數(shù)據(jù)有分析價(jià)值?哪些數(shù)據(jù)可以暫時(shí)不用處理?這些都是部署和實(shí)施大數(shù)據(jù)分析平臺(tái)之前必須梳理的問(wèn)題點(diǎn)。以下就企業(yè)實(shí)施和部署大數(shù)據(jù)平臺(tái),以及如何實(shí)現(xiàn)對(duì)大量數(shù)據(jù)的有效運(yùn)用提供建議。
第一步:采集數(shù)據(jù)
對(duì)企業(yè)而言,不論是新實(shí)施的系統(tǒng)還是老舊系統(tǒng),要實(shí)施大數(shù)據(jù)分析平臺(tái),就需要先弄明白自己到底需要采集哪些數(shù)據(jù)。因?yàn)榭紤]到數(shù)據(jù)的采集難度和成本,大數(shù)據(jù)分析平臺(tái)并不是對(duì)企業(yè)所有的數(shù)據(jù)都進(jìn)行采集,而是相關(guān)的、有直接或者間接聯(lián)系的數(shù)據(jù),企業(yè)要知道哪些數(shù)據(jù)是對(duì)于戰(zhàn)略性的決策或者一些細(xì)節(jié)決策有幫助的,分析出來(lái)的數(shù)據(jù)結(jié)果是有價(jià)值的,這也是考驗(yàn)一個(gè)數(shù)據(jù)分析員的時(shí)刻。比如企業(yè)只是想了解產(chǎn)線設(shè)備的運(yùn)行狀態(tài),這時(shí)候就只需要對(duì)影響產(chǎn)線設(shè)備性能的關(guān)鍵參數(shù)進(jìn)行采集。再比如,在產(chǎn)品售后服務(wù)環(huán)節(jié),企業(yè)需要了解產(chǎn)品使用狀態(tài)、購(gòu)買群體等信息,這些數(shù)據(jù)對(duì)支撐新產(chǎn)品的研發(fā)和市場(chǎng)的預(yù)測(cè)都有著非常重要的價(jià)值。因此,建議企業(yè)在進(jìn)行大數(shù)據(jù)分析規(guī)劃的時(shí)候針對(duì)一個(gè)項(xiàng)目的目標(biāo)進(jìn)行精確的分析,比較容易滿足業(yè)務(wù)的目標(biāo)。
大數(shù)據(jù)的采集過(guò)程的難點(diǎn)主是并發(fā)數(shù)高,因?yàn)橥瑫r(shí)有可能會(huì)有成千上萬(wàn)的用戶來(lái)進(jìn)行訪問(wèn)和操作,比如火車票售票網(wǎng)站和淘寶,它們并發(fā)的訪問(wèn)量在峰值時(shí)達(dá)到上百萬(wàn),所以需要在采集端部署大量數(shù)據(jù)庫(kù)才能支撐。并且如何在這些數(shù)據(jù)庫(kù)之間進(jìn)行負(fù)載均衡和分片也是需要深入的思考問(wèn)題。
第二步:導(dǎo)入及預(yù)處理數(shù)據(jù)
采集過(guò)程只是大數(shù)據(jù)平臺(tái)搭建的第一個(gè)環(huán)節(jié)。當(dāng)確定了哪些數(shù)據(jù)需要采集之后,下一步就需要對(duì)不同來(lái)源的數(shù)據(jù)進(jìn)行統(tǒng)一處理。比如在智能工廠里面可能會(huì)有視頻監(jiān)控?cái)?shù)據(jù)、設(shè)備運(yùn)行數(shù)據(jù)、物料消耗數(shù)據(jù)等,這些數(shù)據(jù)可能是結(jié)構(gòu)化或者非結(jié)構(gòu)化的。這個(gè)時(shí)候企業(yè)需要利用ETL工具將分布的、異構(gòu)數(shù)據(jù)源中的數(shù)據(jù)如關(guān)系數(shù)據(jù)、平面數(shù)據(jù)文件等抽取到臨時(shí)中間層后進(jìn)行清洗、轉(zhuǎn)換、集成,將這些來(lái)自前端的數(shù)據(jù)導(dǎo)入到一個(gè)集中的大型分布式數(shù)據(jù)庫(kù)或者分布式存儲(chǔ)集群,最后加載到數(shù)據(jù)倉(cāng)庫(kù)或數(shù)據(jù)集市中,成為聯(lián)機(jī)分析處理、數(shù)據(jù)挖掘的基礎(chǔ)。對(duì)于數(shù)據(jù)源的導(dǎo)入與預(yù)處理過(guò)程,最大的挑戰(zhàn)主要是導(dǎo)入的數(shù)據(jù)量大,每秒鐘的導(dǎo)入量經(jīng)常會(huì)達(dá)到百兆,甚至千兆級(jí)別。
第三步:統(tǒng)計(jì)與分析
統(tǒng)計(jì)與分析主要利用分布式數(shù)據(jù)庫(kù),或者分布式計(jì)算集群來(lái)對(duì)存儲(chǔ)于其內(nèi)的海量數(shù)據(jù)進(jìn)行普通的分析和分類匯總等,以滿足大多數(shù)常見(jiàn)的分析需求,在這方面,一些實(shí)時(shí)性需求會(huì)用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL的列式存儲(chǔ)Infobright等,而一些批處理,或者基于半結(jié)構(gòu)化數(shù)據(jù)的需求可以使用Hadoop.數(shù)據(jù)的統(tǒng)計(jì)分析方法也很多,如假設(shè)檢驗(yàn)、顯著性檢驗(yàn)、差異分析、相關(guān)分析、T檢驗(yàn)、方差分析、卡方分析、偏相關(guān)分析、距離分析、回歸分析、簡(jiǎn)單回歸分析、多元回歸分析、逐步回歸、回歸預(yù)測(cè)與殘差分析、嶺回歸、logistic回歸分析、曲線估計(jì)、因子分析、聚類分析、主成分分析、因子分析、快速聚類法與聚類法、判別分析、對(duì)應(yīng)分析、多元對(duì)應(yīng)分析(最優(yōu)尺度分析)、bootstrap技術(shù)等等。在統(tǒng)計(jì)與分析這部分,主要特點(diǎn)和挑戰(zhàn)是分析涉及的數(shù)據(jù)量大,其對(duì)系統(tǒng)資源,特別是I/O會(huì)有極大的占用。
第四步:價(jià)值挖掘
與前面統(tǒng)計(jì)和分析過(guò)程不同的是,數(shù)據(jù)挖掘一般沒(méi)有什么預(yù)先設(shè)定好的主題,主要是在現(xiàn)有數(shù)據(jù)上面進(jìn)行基于各種算法的計(jì)算,從而起到預(yù)測(cè)的效果,從而實(shí)現(xiàn)一些高級(jí)別數(shù)據(jù)分析的需求。比較典型算法有用于聚類的Kmeans、用于統(tǒng)計(jì)學(xué)習(xí)的SVM和用于分類的NaiveBayes,主要使用的工具有Hadoop的Mahout等。該過(guò)程的特點(diǎn)和挑戰(zhàn)主要是用于挖掘的算法很復(fù)雜,并且計(jì)算涉及的數(shù)據(jù)量和計(jì)算量都很大,常用數(shù)據(jù)挖掘算法都以單線程為主。
總結(jié)
為了得到更加精確的結(jié)果,在大數(shù)據(jù)分析的過(guò)程要求企業(yè)相關(guān)的業(yè)務(wù)規(guī)則都是已經(jīng)確定好的,這些業(yè)務(wù)規(guī)則可以幫助數(shù)據(jù)分析員評(píng)估他們的工作復(fù)雜性,對(duì)了應(yīng)對(duì)這些數(shù)據(jù)的復(fù)雜性,將數(shù)據(jù)進(jìn)行分析得出有價(jià)值的結(jié)果,才能更好的實(shí)施。制定好了相關(guān)的業(yè)務(wù)規(guī)則之后,數(shù)據(jù)分析員需要對(duì)這些數(shù)據(jù)進(jìn)行分析輸出,因?yàn)楹芏鄷r(shí)候,這些數(shù)據(jù)結(jié)果都是為了更好的進(jìn)行查詢以及用在下一步的決策當(dāng)中使用,如果項(xiàng)目管理團(tuán)隊(duì)的人員和數(shù)據(jù)分析員以及相關(guān)的業(yè)務(wù)部門沒(méi)有進(jìn)行很好的溝通,就會(huì)導(dǎo)致許多項(xiàng)目需要不斷地重復(fù)和重建。最后,由于分析平臺(tái)會(huì)長(zhǎng)期使用,但決策層的需求是變化的,隨著企業(yè)的發(fā)展,會(huì)有很多的新的問(wèn)題出現(xiàn),數(shù)據(jù)分析員的數(shù)據(jù)分析也要及時(shí)的進(jìn)行更新,現(xiàn)在的很多數(shù)據(jù)分析軟件創(chuàng)新的主要方面也是關(guān)于對(duì)數(shù)據(jù)的需求變化部分,可以保持?jǐn)?shù)據(jù)分析結(jié)果的持續(xù)價(jià)值。
官方微信售電那點(diǎn)事兒")
責(zé)任編輯:售電衡衡
免責(zé)聲明:本文僅代表作者個(gè)人觀點(diǎn),與本站無(wú)關(guān)。其原創(chuàng)性以及文中陳述文字和內(nèi)容未經(jīng)本站證實(shí),對(duì)本文以及其中全部或者部分內(nèi)容、文字的真實(shí)性、完整性、及時(shí)性本站不作任何保證或承諾,請(qǐng)讀者僅作參考,并請(qǐng)自行核實(shí)相關(guān)內(nèi)容。
我要收藏
個(gè)贊
- 相關(guān)閱讀
- 碳交易
- 節(jié)能環(huán)保
- 電力法律
- 電力金融
- 綠色電力證書
-

碳中和戰(zhàn)略|趙英民副部長(zhǎng)致辭全文
2020-10-19碳中和,碳排放,趙英民 -

兩部門:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
國(guó)家發(fā)改委、國(guó)家能源局:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè)
-
碳中和戰(zhàn)略|趙英民副部長(zhǎng)致辭全文
2020-10-19碳中和,碳排放,趙英民 -

深度報(bào)告 | 基于分類監(jiān)管與當(dāng)量協(xié)同的碳市場(chǎng)框架設(shè)計(jì)方案
2020-07-21碳市場(chǎng),碳排放,碳交易 -

碳市場(chǎng)讓重慶能源轉(zhuǎn)型與經(jīng)濟(jì)發(fā)展并進(jìn)
2020-07-21碳市場(chǎng),碳排放,重慶
-
兩部門:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
國(guó)家發(fā)改委、國(guó)家能源局:推廣不停電作業(yè)技術(shù) 減少停電時(shí)間和停電次數(shù)
2020-09-28獲得電力,供電可靠性,供電企業(yè) -
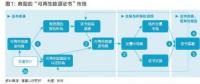
2020年二季度福建省統(tǒng)調(diào)燃煤電廠節(jié)能減排信息披露
2020-07-21火電環(huán)保,燃煤電廠,超低排放
-

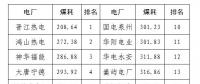
四川“專線供電”身陷違法困境
2019-12-16專線供電 -
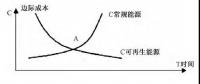
我國(guó)能源替代規(guī)范法律問(wèn)題研究(上)
2019-10-31能源替代規(guī)范法律 -

區(qū)域鏈結(jié)構(gòu)對(duì)于數(shù)據(jù)中心有什么影響?這個(gè)影響是好是壞呢!