踩坑無數,美團點評高可用數據庫架構演進

同時,也和業界其他方案進行綜合對比,了解業界在高可用方面的進展和未來我們的一些規劃和展望。
MMM
在 2015 年之前,美團點評(點評側)長期使用 MMM(Master-Master replication manager for MySQL)做數據庫高可用。
因此我們積累了比較多的經驗,但也踩了不少坑,可以說 MMM 在公司數據庫高速發展過程中起到了很大的作用。
MMM 的架構如下:
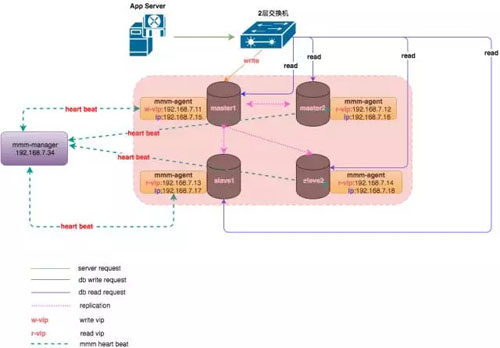
如上圖所示,整個 MySQL 集群提供 1 個寫 VIP(Virtual IP)和 N(N>=1)個讀 VIP 的對外服務。
每個 MySQL 節點均部署有一個 Agent(mmm-agent),mmm-agent 和 mmm-manager 保持通信狀態,定期向 mmm-manager 上報當前 MySQL 節點的存活情況(這里稱之為心跳)。
當 mmm-manager 連續多次無法收到 mmm-agent 的心跳消息時,會進行切換操作。
mmm-manager 分兩種情況處理出現的異常:
- 出現異常的是從節點,mmm-manager 會嘗試摘掉該從節點的讀 VIP,并將該讀 VIP 漂移到其他存活的節點上,通過這種方式實現從庫的高可用。
- 出現異常的是主節點,如果當時節點還沒完全掛,只是響應超時,則嘗試將 Dead Master 加上全局鎖(flush tables with read lock),在從節點中選擇一個候選主節點作為新的主節點,進行數據補齊。
數據補齊之后,摘掉 Dead Master 的寫 VIP,并嘗試加到新的主節點上。將其他存活的節點進行數據補齊,并重新掛載在新的主節點上。
主庫發生故障后,整個集群狀態變化如下:
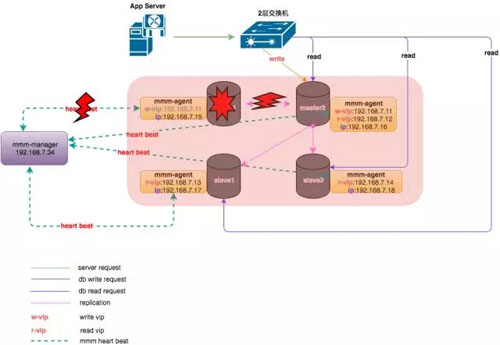
mmm-manager 檢測到 master1 發生了故障,對數據進行補齊之后,將寫 VIP 漂移到了 master2 上,應用寫操作在新的節點上繼續進行。
然而,MMM 架構存在如下問題:
- VIP 的數量過多,管理困難(曾經有一個集群是 1 主 6 從,共計 7 個 VIP)。某些情況下會導致集群大部分 VIP 同時丟失,很難分清節點上之前使用的是哪個 VIP。
- mmm-agent 過度敏感,容易導致 VIP 丟失。同時 mmm-agent 自身由于沒有高可用,一旦掛掉,會造成 mmm-manager 誤判,誤認為 MySQL 節點異常。
- mmm-manager 存在單點,一旦由于某些原因掛掉,整個集群就失去了高可用。
- VIP 需要使用 ARP 協議,跨網段、跨機房的高可用基本無法實現,保障能力有限。
同時,MMM 是 Google 技術團隊開發的一款比較老的高可用產品,在業內使用的并不多,社區也不活躍,Google 很早就不再維護 MMM 的代碼分支。
我們在使用過程中發現大量 Bug,部分 Bug 我們做了修改,并提交到開源社區。
MHA
針對于此,從 2015 年開始,美團點評對 MySQL 高可用架構進行了改進,全部更新為 MHA,很大程度上解決了之前 MMM 遇到的各種問題。
MHA(MySQL Master High Availability)是由 Facebook 工程師 Yoshinori Matsunobu 開發的一款 MySQL 高可用軟件,從名字就可以看出,MHA 只負責 MySQL 主庫的高可用。
當主庫發生故障時,MHA 會選擇一個數據最接近原主庫的候選主節點(這里只有一個從節點,所以該從節點即為候選主節點)作為新的主節點,并補齊和之前 Dead Master 差異的 Binlog。數據補齊之后,即將寫 VIP 漂移到新主庫上。
整個 MHA 的架構如下(為簡單起見,只描述一主一從):

這里我們對 MHA 做了一些優化,避免一些腦裂問題。
比如 DB 服務器的上聯交換機出現了抖動,導致主庫無法訪問,被管理節點判定為故障,觸發 MHA 切換,VIP 被漂到了新主庫上。
隨后交換機恢復,主庫可被訪問,但由于 VIP 并沒有從主庫上摘除,因此 2 臺機器同時擁有 VIP,會產生腦裂。
我們對 MHA Manager 加入了向同機架上其他物理機的探測,通過對比更多的信息來判斷是網絡故障還是單機故障。
MHA+Zebra(DAL)
Zebra(斑馬)是美團點評基礎架構團隊開發的一個 Java 數據庫訪問中間件。
它是在 c3p0 基礎上包裝的美團點評內部使用的動態數據源,包括讀寫分離、分庫分表、SQL 流控等非常強的功能,它和 MHA 配合,成為了 MySQL 數據庫高可用的重要一環。
如下是 MHA+Zebra 配合的整體架構:

以主庫發生故障為例,處理邏輯有如下兩種方式:
- 當 MHA 切換完成之后,主動發送消息給 Zebra monitor,Zebra monitor 更新 ZooKeeper 的配置,將主庫上配置的讀流量標記為下線狀態。
- Zebra monitor 每隔一段時間(10s ~ 40s)檢測集群中節點的健康狀況,一旦發現某個節點出現了問題,及時刷新 ZooKeeper 中的配置,將該節點標記為下線。
一旦節點變更完成,客戶端監聽到節點發生了變更,會立即使用新的配置重建連接,而老的連接會逐步關閉。
整個集群故障切換的過程如下(僅描述 Zebra monitor 主動探測的情況,第一種 MHA 通知請自行腦補^_^)。

由于該切換過程還是借助于 VIP 漂移,導致只能在同網段或者說同個二層交換機下進行,無法做到跨網段或者跨機房的高可用。
為解決這個問題,我們對 MHA 進行了二次開發,將 MHA 添加 VIP 的操作去掉,切換完之后通知 Zebra monitor 去重新調整節點的讀寫信息(將 Write 調整為 new master 的實 IP,將 Dead Master 的讀流量摘除)。
整個切換就完全去 VIP 化,做到跨網段、甚至跨機房切換,徹底解決之前高可用僅局限于同網段的問題。
上述切換過程就變成了如下圖:

然而,這種方式中的 MHA 管理節點是單點,在網絡故障或者機器宕機情況下依然存在風險。
同時,由于 Master-Slave 之間是基于 Binlog 的異步復制,也就導致了主庫機器宕機或者主庫無法訪問時,MHA 切換過程中可能導致數據丟失。
另外,當 Master-Slave 延遲太大時,也會給數據補齊這一操作帶來額外的時間開銷。
Proxy
除了 Zebra 中間件,美團點評還有一套基于 Proxy 的中間件和 MHA 一起配合使用。
當 MHA 切換后,主動通知 Proxy 來進行讀寫流量調整,Proxy 相比 Zebra 更加靈活,同時也能覆蓋非 Java 應用場景。
缺點就是訪問鏈路多了一層,對應的 Response Time 和故障率也有一定增加。
未來架構設想
MHA 架構依然存在如下兩個問題:
- 管理節點單點
- MySQL 異步復制中的數據丟失
針對于此,我們在部分核心業務上使用 Semi-Sync,可以保證 95% 以上場景下數據不丟失(依然存在一些極端情況下無法保障數據的強一致性)。
另外,高可用使用分布式的 Agent,在某個節點發生故障后,通過一定的選舉協議來選擇新的 Master,從而解決了 MHA Manager 的單點問題。
針對上述問題,我們研究了業界的一些領先的做法,簡單描述如下。
主從同步數據丟失
針對主從同步的數據丟失,一種做法是創建一個 Binlog Server,該 Server 模擬 Slave 接受 Binlog 日志,主庫每次的數據寫入都需要接收到 Binlog Server 的 ACK 應答,才認為寫入成功。
Binlog Server 可以部署在就近的物理節點上,從而保證每次數據寫入都能快速落地到 Binlog Server。
在發生故障時,只需要從 Binlog Server 拉取數據即可保證數據不丟失。
分布式 Agent 高可用
針對 MHA 管理節點單點問題,一種做法是讓 MySQL 數據庫集群中每個節點部署 Agent,當發生故障時,每個 Agent 均參與選舉投票,選舉出合適的 Slave 作為新的主庫,防止只通過 Manager 來切換,去除 MHA 單點。
整個架構如下圖所示:

MGB 結合中間件高可用
上述方式某種程度上解決了之前的問題,但是 Agent 和 Binlog Server 卻是新引入的風險,同時 Binlog Server 的存在,也帶來了響應時間上的額外開銷。
有沒有一種方式,能夠去除 Binlog Server 和 Agent,又能保證數據不丟失呢 ?答案當然是有的。
最近幾年,MySQL 社區關于分布式協議 Raft 和 Paxos 非常火,社區也推出了基于 Paxos 的 MGR 版本的 MySQL,通過 Paxos 將一致性和切換過程下推到數據庫內部,向上層屏蔽了切換細節。
架構如下(以 MGR 的 single-primary 為例):

當數據庫發生故障時,MySQL 內部自己進行切換。切換完成后將 topo 結構推送給 Zebra monitor,Zebra monitor 進行相應的讀寫流量變更。
不過,該架構存在與 Binlog Server 同樣的需要回復確認問題,就是每次主庫數據寫入,都需要大多數節點回復 ACK,該次寫入才算成功,存在一定的響應時間開銷。
同時,每個 MGR 集群必須需要奇數個數(大于 1)的節點,導致原先只需要一主一從兩臺機器,現在需要至少三臺,帶來一定的資源浪費。
但不管怎么說,MGR 的出現無疑是 MySQL 數據庫又一次偉大的創新。
結語
本文介紹了美團點評 MySQL 數據庫高可用架構從 MMM 到 MHA+Zebra 以及 MHA+Proxy 的演進歷程,同時也介紹了業界一些高可用的做法。
數據庫最近幾年的發展突飛猛進,數據庫的高可用設計上沒有完美的方案,只有不斷的突破和創新,我們也一直在這條路上探索更加優秀的設計與更加完美的方案。

責任編輯:售電衡衡
-

碳中和戰略|趙英民副部長致辭全文
2020-10-19碳中和,碳排放,趙英民 -

兩部門:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業 -
國家發改委、國家能源局:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業
-
碳中和戰略|趙英民副部長致辭全文
2020-10-19碳中和,碳排放,趙英民 -

深度報告 | 基于分類監管與當量協同的碳市場框架設計方案
2020-07-21碳市場,碳排放,碳交易 -

碳市場讓重慶能源轉型與經濟發展并進
2020-07-21碳市場,碳排放,重慶
-
兩部門:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業 -
國家發改委、國家能源局:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業 -
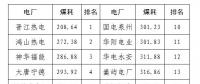
2020年二季度福建省統調燃煤電廠節能減排信息披露
2020-07-21火電環保,燃煤電廠,超低排放
-

四川“專線供電”身陷違法困境
2019-12-16專線供電 -
我國能源替代規范法律問題研究(上)
2019-10-31能源替代規范法律 -

區域鏈結構對于數據中心有什么影響?這個影響是好是壞呢!