大數據分析到底需要多少種工具?
大數據如今已經不再是什么新的名詞,五中全會大數據上升為國家戰略,BAT巨頭早已布局多年,大數據時代已經真正來臨,但我們真的準備好了么?
大家都知道大數據中蘊含大量的數據價值,比如說淘寶與天貓的用戶消費行為、滴滴打車可以知道用戶每天去了哪里、用戶在優酷上都看了那些視頻、移動運營商的海量客戶終端信息以及上網行為等、大型零售商每天的銷售數據,訂餐網上用戶每天吃了什么,等等大數據金礦無處不在。但淘出來的才是金子,否則只是一堆土而 已,即占用場地,還要花錢去保管和維護這堆土。
大數據時代金礦已經有了,如何利用好這個金礦,某種意義上取決于我們手上的工具。熟話說“沒有那金剛鉆,就別攬瓷器活”,工具是否適用,直接決定著我們能否進行挖金,以及挖金的速度與效率。適合用鐵鍬還是挖掘機,對挖金來說有著質的不同。
第一個金剛鉆Hadoop
Hadoop是大數據時代的第一個金剛鉆。筆者從08年開始研究hadoop源碼,當時中文資料還是比較少的,國內除了BAT外其他公司用的也很少,初次 接觸hadoop是因為被當時公司的流量系統所困擾,當時公司網站的流量已經達到了每天接近一個億的水平,最初選擇了postgresql來計算數據,但 是普通機器根本無法計算,無奈之下我們花大價錢買了128G內存(在當時是很奢侈的)的服務器,運行在postgresql的內存表里才勉勉強強的計算出 來。直到有一天遇到了hadoop,你懂的,一個HiveSql在幾臺普通硬件的機器上,一億數據幾個小時就出結果了。
如今Hadoop已經不再神秘,相關書籍越來越多。但是伴隨著互聯網技術的日新月異,Hadoop已經不能滿足用戶了。數據時效性差,以及查詢的響應效率 低,那些對時效性要求較高的用戶場景無法滿足。Hadoo目前面臨兩兩方面的挑戰,第一,數據從產生到能夠最終出結果要等待數小時,時效性較差。第二,多 個Job任務,相互之間爭搶資源,而且由于采用暴力掃描原始數據的方式,對機器資源的消耗太大,每天能夠跑的計算任務個數十分有限。
第二個利器阿里JStorm
JStorm的出現主要是因為Hadoop滿足不了支付寶成交實時分析的需求。阿里的雙十一活動以及其他活動都有對阿里網站成交流量實時展示的需求,通過運營活動,來了解開始的幾分鐘或者幾秒鐘內,實時流入了多少的流量,帶來多大的成交。正巧當時Apache Storm正式開源,阿里團隊認為Storm正適合阿里的業務,但是Storm的核心邏輯采用Clojure編寫,熟悉這門語言的太少,另外業務需要定制 化的邏輯,故阿里團隊花費3個多月的時間閱讀Storm的源碼,并將其Clojure部分更換為Java代碼。筆者曾是團隊的一員,有幸成為其 committer,離開阿里后,團隊其他兄弟將其開源,貢獻了出去,如今Jstorm已經被Apache接受,正式成為Storm項目的子項目。
Storm能夠滿足企業對數據時效性的要求,但跟現有的其他大數據的實時系統一樣,都是采用預計算的方式。因流式系統不保存原始日志,數據只能安裝固定的 維度和粒度進行計算與匯總,例如只能按照淘寶的類目、分鐘等維度匯總統計。眾所周知,運營情況是千遍萬化的,很多都是突發事件,維度并不能預先固定,很多 事物也需要多方面展示,要經過數次的不同角度、不同粒度的鉆取,來發現運營活動的規律。基于這種場景,我們需要保留原始日志,同時需要非常快速的對這些原 始日志進行快分析與計算。這樣高需求的場景,數據工具既要有hadoop+hive計算的靈活性,又要有Jstorm的時效性和速度。Storm就顯出了 它的不足。
新生代數據挖掘機延云YDB
YDB是延云針對用戶對大數據檢索快速、實時、多維度的需求而開發的分析軟件,可以說是筆者的心頭好。
YDB將傳統數據庫索引技術應用在大數據技術上,打破目前大數據計算技術的僵局。將大數據檢索向時效性更強,查詢方式更 靈活,執行效率更高的方向演進。雖然引用傳統索引技術,但是對硬件的需求并不比hadoop高,不會讓小型用戶望而卻步。技術上YDB采用Java語言編 寫,接地氣,Sql接口用戶也更易于上手使用,同時每天千億增量萬億總量的數據量也能滿足高端用戶的需求。YDB主要技術方向在大索引,大索引的好處在于 加快了檢索的速度,減少查詢中的分組、統計和排序時間,提高系統的性能和響應時間來節約資源。大索引技術的運用才能使YDB在如此大規模的數據量下依然保 持查詢響應時間在幾秒,數據導入延遲在幾分鐘。

責任編輯:售電衡衡
-

碳中和戰略|趙英民副部長致辭全文
2020-10-19碳中和,碳排放,趙英民 -

兩部門:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業 -
國家發改委、國家能源局:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業
-
碳中和戰略|趙英民副部長致辭全文
2020-10-19碳中和,碳排放,趙英民 -

深度報告 | 基于分類監管與當量協同的碳市場框架設計方案
2020-07-21碳市場,碳排放,碳交易 -

碳市場讓重慶能源轉型與經濟發展并進
2020-07-21碳市場,碳排放,重慶
-
兩部門:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業 -
國家發改委、國家能源局:推廣不停電作業技術 減少停電時間和停電次數
2020-09-28獲得電力,供電可靠性,供電企業 -
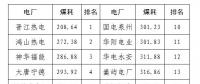
2020年二季度福建省統調燃煤電廠節能減排信息披露
2020-07-21火電環保,燃煤電廠,超低排放
-

四川“專線供電”身陷違法困境
2019-12-16專線供電 -
我國能源替代規范法律問題研究(上)
2019-10-31能源替代規范法律 -

區域鏈結構對于數據中心有什么影響?這個影響是好是壞呢!