
【應用】撩開分布式存儲神秘面紗
VBS是計算數據塊存儲位置的重要網元。一個VBS就是一個“機頭”。VBS部署很靈活,有很多種部署方法,可以根據不同的需求進行選擇。比如,在VMWARE虛擬機中,可以在物理機上開設一臺虛擬機部署VBS,在XEN/KVM部署在domain0上;或者部署在每臺OSD服務器上,或專門設置VBS服務器群。

VBS采取一致性哈希算法,如圖3,將數據塊的邏輯地址計算出KEY值。并將計算出來的KEY映射到哈希環上,在哈希環上劃分了N段(Partition),每個Partition對應一個硬盤,并根據出partition主和osd節點的映射關系ioview,和partitio主備對應的osd關系,得到該數據塊的路由,如圖4。在寫入的時候,采用強一致性,即當主和備副本都返回寫成功后,才認為這個IO寫成功了。讀IO時只讀主副本,當主副本故障的時候,會在備副本中選舉出主副本。目前,一個資源池可以支持2000塊硬盤。
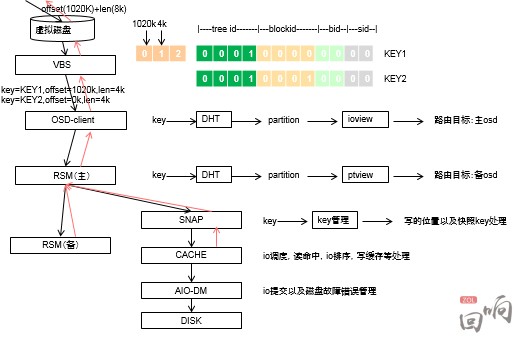
操作系統看到的連續的數據邏輯地址(LBA),實際上被打散到資源池內所有硬盤上了,類似所有硬盤都做了raid0,這樣就利用了所有磁盤的性能,提高了存儲的性能。操作系統實際是直接讀寫物理磁盤的塊,并沒有封裝額外的文件系統,是一個raw設備。
OSD是一臺插了較多硬盤的X86服務器,我們采用的是12塊SATA3T的硬盤作為數據的持久化存儲介質。如果VBS不承載在OSD上,那么OSD服務器的計算壓力實際上很小,也沒有必要配置計算能力很強、內存配置很高的服務器。上一篇文章計算過,12塊SATA盤提供的iops或吞吐量其實很有限,需要配置SSD作為緩存,加速存儲的性能。由此看來,分布式存儲的性能是由SSD的性能和熱點數據計算算法決定的。和一般存儲不同,一般分布式存儲的寫性能會好于讀性能。主要是主和備副本寫入SSD就返回成功了,而SSD什么時候寫入硬盤,怎么寫入硬盤,客戶端是不知道的。而讀數據的時候,如果數據是熱點數據,已經在緩存在SSD上,性能會很好,如果沒有在緩存中,就需要到硬盤中直接讀取,那性能就很差了。這也是當分布式存儲在初始化的時候,測試性能指標不如運行一段時間后的指標。所以測試分布式存儲有很多陷阱,大家要注意。
為了提高存儲的安全性,達到6個9以上的安全性,我們采取的是通行的3副本(2副本在96塊盤以下,可以達到6個9)。副本可以根據實際情況設置成為在不同機架、不同服務器、不同硬盤的安全級別。當磁盤或主機故障,會被MDC監控到,會選舉主副本、踢出故障點、重構副本等操作。為了確保數據的安全,副本重構的時間很關鍵,我們要求,每T數據重構時間不超過30分鐘。
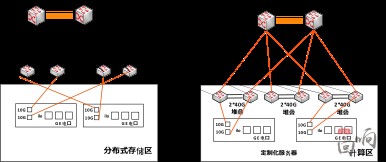
為了確保數據重構流量不影響正常存儲IO訪問流量,實現快速數據重構。我們沒有采取華為推薦的網絡方案,而是采用環形虛擬化堆疊的方案,交換機間的堆疊鏈路采用40G光路,如圖5。將存儲的重構流量都壓制在存儲環形網絡中。交換機到服務器采用2*10G連接,可以根據情況采用主備或分擔的模式。
說過了“塊”存儲,再簡單了解一下“對象存儲”。對象存儲是在同樣容量下提供的存儲性能比文件存儲更好,又能像文件存儲一樣有很好的共享性。實際使用中,性能不是對象存儲最關注的問題,需要高性能可以用塊存儲,容量才是對象存儲最關注的問題。所以對象存儲的持久化層的硬盤數量更多,單盤的容量也更大。對象存儲的數據的安全性保障也各式各樣,可以是單機raid或網絡raid,也可以副本。對性能要求不高,可以直接用普通磁盤,或利用raid卡的緩存,也可以配些SSD作為緩存。我們現在使用單機35塊7200轉4TSATA盤+raid卡緩存加速的自研對象存儲,并計劃在今年使用60塊7200轉8TSATA盤。即每臺服務器提供480T的裸容量。Ceph和google基于GFS的存儲就是典型的對象存儲。
Ceph是目前最為熱門的存儲,可以支持多種接口。Ceph存儲的架構和華為的FusionStorage異曲同工,都是靠“算”而不是“查”。一種是為數眾多的、負責完成數據存儲和維護功能的OSD,另一種則是若干個負責完成系統狀態檢測和維護的monitor。OSD和monitor之間相互傳輸節點狀態信息,共同得出系統的總體工作狀態,并形成一個全局系統狀態記錄數據結構,即所謂的clustermap。這個數據結構與特定算法相配合,便實現了Ceph“無需查表,算算就好”的核心機制以及若干優秀特性。
但數據的的組織方法是不同的。首先ceph的核心是一個對象存儲,是以對象為最小組織單位。1、首先文件是被映射成為一個或多個對象。2、然后每個對象再被映射到PG(PlacementGroup)上,PG和對象之間是“一對多”映射關系。3、而PG會映射到n個OSD上,n就是副本數,OSD和PG是“多對多”的關系。
由若干個monitor共同負責整個Ceph集群中所有OSD狀態的發現與記錄,并且共同形成clustermap的master版本,然后擴散至全體OSD以及客戶端。OSD使用clustermap進行數據的維護,而客戶端使用clustermap進行數據的尋址。
Google三大寶之一的“GFS”是google對象存儲的基礎。
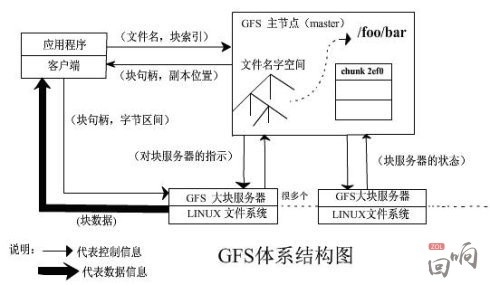
核心不同是數據的組織架構:master服務器(即元數據服務器)保存了文件名和塊的名字空間、從文件到塊的映射、副本位置,由客戶端來查詢。是一個典型的信令和媒體分開的架構。
分布式存儲一般情況下都是靠“副本”來確保數據的安全性和完整性。每塊盤記錄的數據內容都不一樣,當某一塊盤出現問題,都需要從其他不同盤內的數據塊中進行快速的數據重構。數據重構是需要時間的,如果大量盤同時故障,將會發生什么?另外,OSD的擴容,也會導致數據的遷移,也會影響存儲。下一篇,我將最終揭開分布式存儲存在的隱患。

責任編輯:蔣桂云
-

重新審視“雙循環”下的光伏行業
2020-11-02光伏行業,光伏技術,光伏出口 -
能源轉型進程中火電企業的下一程
2020-11-02五大發電,火電,煤電 -

國內最高額定水頭抽蓄電站2#引水上斜井滑模混凝土施工順利完成
2020-10-30抽水蓄能電站,長龍山抽水蓄能電站,水力發電
-
能源轉型進程中火電企業的下一程
2020-11-02五大發電,火電,煤電 -
資本市場:深度研究火電行業價值
2020-07-09火電,火電公司,電力行業 -

國家能源局印發2020年能源工作指導意見:從嚴控制、按需推動煤電項目建設
2020-06-29煤電,能源轉型,國家能源局
-

高塔技術助力分散式風電平價上網
2020-10-15分散式風電,風電塔筒,北京國際風能大會 -

創造12項世界第一!世界首個柔性直流電網工程組網成功
2020-06-29?清潔能源,多能互補,風電 -

桂山風電項目部組織集體默哀儀式
2020-04-08桂山風電項目部組織
-
國內最高額定水頭抽蓄電站2#引水上斜井滑模混凝土施工順利完成
2020-10-30抽水蓄能電站,長龍山抽水蓄能電站,水力發電 -
今后秦嶺生態環境保護區內不再審批和新建小水電站
2020-06-29小水電,水電站,水電 -

3.2GW!能源局同意確定河北新增三個抽水蓄能電站選點規劃
2020-06-29抽水蓄能,抽水蓄能電站,國家能源局
-
重新審視“雙循環”下的光伏行業
2020-11-02光伏行業,光伏技術,光伏出口 -

官司纏身、高層動蕩、工廠停產 “保殼之王”天龍光電將被ST
2020-09-11天龍光電,光伏設備,光伏企業現狀 -

央視財經熱評丨光伏發電的平價時代到了嗎?
2020-08-24儲能,光伏儲能,平價上網
